
6개월 사이에 인공지능(AI) 칩의 추론 속도가 무려 3배나 빨라진 것으로 나타났다. 이를 통해 AI 발전이 더 빨라질 것이라는 예상이 가능하게 됐다.
벤처비트는 27일(현지시간) ML커먼스가 'ML퍼프(MLPerf) 4.0' 추론 벤치마크 결과를 발표했다고 전했다.
이는 지난해 9월 'ML퍼프 3.1' 결과가 공개된 이후 첫번째 업데이트다.
이번 벤치마크에는 ▲텍스트 요약 벤치마크를 위한 ‘GPT-J 6B’ ▲LLM에 질문 및 답변(Q&A) 벤치마크를 위해 메타의 오픈 소스 LLM ‘라마 2 70B’ 등이 추가됐다. 또 ML퍼프에는 처음으로 ▲‘스테이블 디퓨전’을 사용한 이미지 생성 AI에 대한 벤치마크도 포함됐다.
엔비디아는 이번에도 인상적인 결과로 ML퍼프 벤치마크를 장악했다.
‘텐서RT-LLM’ 기술을 사용해 H100 호퍼 GPU의 GPT-J LLM을 통해 텍스트 요약에 대한 추론 성능을 거의 3배 향상한 결과를 만들어 냈다. 텐서RT-LLM은 GPU에서 LLM 추론을 가속화하고 최적화하는 엔비디아의 오픈 소스 소프트웨어다.
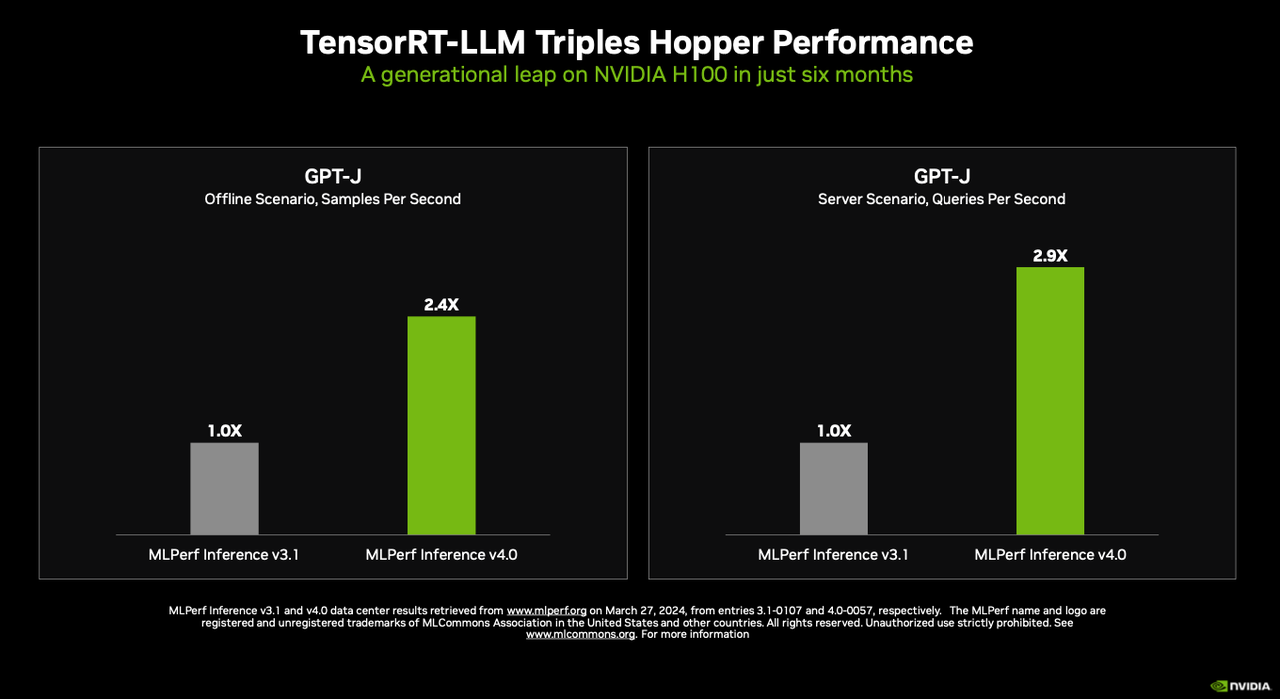
데이브 살바토르 엔비디아 가속 컴퓨팅 이사는 “불과 6개월 만에 3배의 성능 향상이 이뤄졌다”라며 “우리 엔지니어링 팀은 호퍼 아키텍처에서 더 많은 성능을 추출할 수 있는 방법을 찾기 위해 계속 노력 중"이라고 강조했다.
지난주 GTC에서 발표한 호퍼 아키텍처의 후속 제품 ‘블랙웰 GPU’에 대한 벤치마크는 수행하지 않았다. 대신 'H200' GPU의 추론 벤치마크 결과를 최초로 공개했다. 추론을 위해 라마 2를 활용할 경우, H200은 H100보다 최대 45% 빨랐다.
한편 인텔은 하바나 AI 가속기 ‘가우디’와 ‘제온’ CPU 기술을 사용해 ML퍼프 4.0 벤치마크에 참여했다.
가우디는 엔비디아 H100의 성능에 미치지 못했다. 하지만 인텔은 "이 정도 성능을 발휘하는 가우디가 엔비디아보다 저렴하기 때문에 충분한 경쟁력을 갖췄다"라고 강조했다.
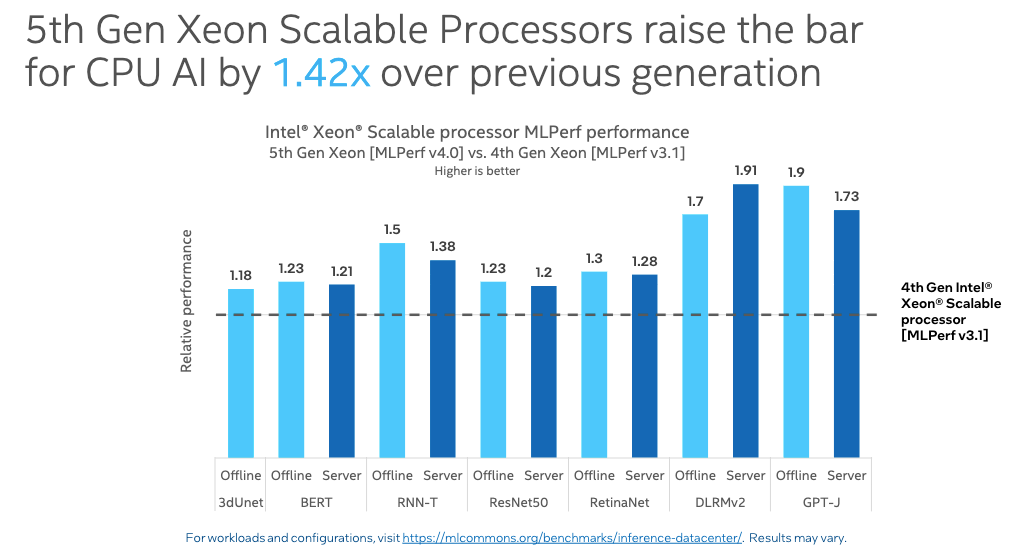
또 5세대 제온 CPU가 이전 4세대 제온 CPU보다 추론 속도가 1.42배 빠른 것으로 나타났다. 구체적으로 GPT-J LLM 텍스트 요약 사용 사례만 보면 5세대 제온이 최대 1.9배 더 빨랐다.
로낙 샤 인텔 제온 AI 제품 이사는 "많은 기업은 AI 전용 인프라는 물론 일반 환경에서도 AI 솔루션을 배포하게 될 것"이라며 "그래서 우리는 AMX 엔진을 통해 강력한 AI 기능과 강력한 범용 기능을 결합하는 CPU를 설계했다"라고 설명했다.
박찬 기자 cpark@aitimes.com
무단전재 및 재배포 금지
기사제보 및 보도자료 news@aitimes.com